どうも、nippa です。
天文分野でよく使われれる FITS 形式のファイルを操作する必要があり、記事にまとめて おきたいと思います。
FITS 形式のファイルを扱うにはいくつかライブラリがあります。
今回、Python での操作を前提として、astropy を利用して操作したいと思います。
環境
FITS ファイル形式
FITS ファイルは複数の「ヘッダーデータユニット」(HDU)で構成されています。各 HDU は、ヘッダー部とデータ部の 2 つのセクションから成り立っています。
ヘッダーは ASCII テキストで記述されており、データの詳細が含まれています。データ 部分はバイナリ形式で記述されており、任意の形式の配列データが含まれて言います。
astropy を利用した FITS ファイルの操作
astropy のインストール
- pip インストール
pip install astropy
- poetry インストール
poetry add astropy
FITS ファイルのサンプルの取得
NASA のサイトから FITS ファイルのサンプルを取得します。
https://fits.gsfc.nasa.gov/fits_samples.html
ブラウザから取得することもできます。
- curl での取得
curl -o WFPC2u5780205r_c0fx.fits https://fits.gsfc.nasa.gov/samples/WFPC2u5780205r_c0fx.fits
- wget での取得
wget https://fits.gsfc.nasa.gov/samples/WFPC2u5780205r_c0fx.fits
FITS ファイルの読み込み
astorpy.io を利用して、データを読み込みます。
from astropy.io import fits file_name = "WFPC2u5780205r_c0fx.fits" hdul = fits.open(file_name)
FITS ファイルのヘッダー情報の表示
header 情報は dict 形式として取得できます。
from astropy.io import fits file_name = "WFPC2u5780205r_c0fx.fits" hdul = fits.open(file_name) header = hdul[0].header for key, value in header.items(): print(f"{key}: {value}")
実行すると以下のような出力がされます。
SIMPLE: True BITPIX: -32 NAXIS: 3 NAXIS1: 200 NAXIS2: 200 NAXIS3: 4 EXTEND: True COMMENT: FITS (Flexible Image Transport System) format is defined in 'Astronomy COMMENT: and Astrophysics', volume 376, page 359; bibcode: 2001A&A...376..359H BSCALE: 1.0 BZERO: 0.0 OPSIZE: 2112 ORIGIN: STScI-STSDAS FITSDATE: 2004-01-09 FILENAME: u5780205r_cvt.c0h ALLG-MAX: 3777.701 ALLG-MIN: -73.19537 ODATTYPE: FLOATING SDASMGNU: 4 CRVAL1: 182.6311886308 CRVAL2: 39.39633673411 CRPIX1: 420.0 CRPIX2: 424.5 CD1_1: -1.06704e-06 CD1_2: -1.25958e-05 CD2_1: -1.26016e-05 CD2_2: 1.06655e-06 DATAMIN: -73.19537 DATAMAX: 3777.701 MIR_REVR: True ORIENTAT: -85.16 FILLCNT: 0 ERRCNT: 0 FPKTTIME: 51229.798574 LPKTTIME: 51229.798742 CTYPE1: RA---TAN CTYPE2: DEC--TAN DETECTOR: 1 DEZERO: 316.6452 BIASEVEN: 316.6715 BIASODD: 316.6189 GOODMIN: -5.064006 GOODMAX: 2552.17 DATAMEAN: 0.4182382 GPIXELS: 632387 SOFTERRS: 0 CALIBDEF: 1466 STATICD: 0 ATODSAT: 16 DATALOST: 0 BADPIXEL: 0 OVERLAP: 0 PHOTMODE: WFPC2,1,A2D7,LRF#4877.0,,CAL PHOTFLAM: 3.44746e-16 PHOTZPT: -21.1 PHOTPLAM: 4884.258 PHOTBW: 20.20996 MEDIAN: -0.175651 MEDSHADO: -0.121681 HISTWIDE: 1.033711 SKEWNESS: -1.983727 MEANC10: 0.12958 MEANC25: 0.3129676 MEANC50: 0.4577668 MEANC100: 0.3916293 MEANC200: 0.3115222 MEANC300: 0.3295493 BACKGRND: -0.3676353 ORIGIN: NOAO-IRAF FITS Image Kernel December 2001 DATE: 2004-01-09T03:26:36 IRAF-TLM: 03:26:36 (09/01/2004) FILETYPE: SCI : TELESCOP: HST INSTRUME: WFPC2 EQUINOX: 2000.0 : : / WFPC-II DATA DESCRIPTOR KEYWORDS : ROOTNAME: u5780205r PROCTIME: 53013.14019676 OPUS_VER: OPUS 14.5a CAL_VER: : : / SCIENCE INSTRUMENT CONFIGURATION : MODE: FULL SERIALS: OFF : : / IMAGE TYPE CHARACTERISTICS : IMAGETYP: EXT CDBSFILE: NO PKTFMT: 96 : : / FILTER CONFIGURATION : FILTNAM1: FR533P15 FILTNAM2: FILTER1: 69 FILTER2: 0 FILTROT: 15.0 LRFWAVE: 4877.0 : : / INSTRUMENT STATUS USED IN DATA PROCESSING : UCH1CJTM: -88.2569 UCH2CJTM: -88.6697 UCH3CJTM: -88.3028 UCH4CJTM: -88.7671 UBAY3TMP: 13.2302 KSPOTS: OFF SHUTTER: A ATODGAIN: 7.0 : : / RSDP CONTROL KEYWORDS : MASKCORR: COMPLETE ATODCORR: COMPLETE BLEVCORR: COMPLETE BIASCORR: COMPLETE DARKCORR: COMPLETE FLATCORR: SKIPPED SHADCORR: OMIT DOSATMAP: OMIT DOPHOTOM: COMPLETE DOHISTOS: OMIT OUTDTYPE: REAL : : / CALIBRATION REFERENCE FILES : MASKFILE: uref$f8213081u.r0h ATODFILE: uref$dbu1405iu.r1h BLEVFILE: ucal$u5780205r.x0h BLEVDFIL: ucal$u5780205r.q1h BIASFILE: uref$j9a1612mu.r2h BIASDFIL: uref$j9a1612mu.b2h DARKFILE: uref$j2g1549cu.r3h DARKDFIL: uref$j2g1549cu.b3h FLATFILE: uref$f4i1559cu.r4h FLATDFIL: uref$f4i1559cu.b4h SHADFILE: uref$e371355eu.r5h PHOTTAB: u5780205r_c3t.fits GRAPHTAB: mtab$n9i1408hm_tmg.fits COMPTAB: mtab$nc809508m_tmc.fits : : / DEFAULT KEYWORDS SET BY STSCI : SATURATE: 4095 USCALE: 1.0 UZERO: 0.0 : : / READOUT DURATION INFORMATION : READTIME: 464 : : / PLANETARY SCIENCE KEYWORDS : PA_V3: 49.936909 RA_SUN: 333.7194516616 DEC_SUN: -10.86675160382 EQNX_SUN: 2000.0 MTFLAG: False EQRADTRG: 0.0 FLATNTRG: 0.0 NPDECTRG: 0.0 NPRATRG: 0.0 ROTRTTRG: 0.0 LONGPMER: 0.0 EPLONGPM: 0.0 SURFLATD: 0.0 SURFLONG: 0.0 SURFALTD: 0.0 : : / PODPS FILL VALUES : PODPSFF: 0 STDCFFF: 0 STDCFFP: 0x5569 RSDPFILL: -100 : : / EXPOSURE TIME AND RELATED INFORMATION : UEXPODUR: 300 NSHUTA17: 1 DARKTIME: 300.0 UEXPOTIM: 16880 PSTRTIME: 1999.051:19:08:37 PSTPTIME: 1999.051:19:16:37 : : / EXPOSURE INFORMATION : SUNANGLE: 141.618347 MOONANGL: 126.698997 SUN_ALT: -31.523479 FGSLOCK: FINE : DATE-OBS: 1999-02-20 TIME-OBS: 19:03:13 EXPSTART: 51229.79390428 EXPEND: 51229.7973765 EXPTIME: 300.0 EXPFLAG: NORMAL : : / TARGET & PROPOSAL ID TARGNAME: NGC4151 RA_TARG: 182.6355 DEC_TARG: 39.40576666667 ECL_LONG: 164.096619 ECL_LAT: 36.623709 GAL_LONG: 155.079532 GAL_LAT: 75.062679 : PROPOSID: 8019 PEP_EXPO: 02-030 LINENUM: 02.030 SEQLINE: SEQNAME: HISTORY: MASKFILE=uref$f8213081u.r0h MASKCORR=COMPLETED HISTORY: PEDIGREE=INFLIGHT 01/01/1994 - 15/05/1995 HISTORY: DESCRIP=STATIC MASK - INCLUDES CHARGE TRANSFER TRAPS HISTORY: BIASFILE=uref$j9a1612mu.r2h BIASCORR=COMPLETED HISTORY: PEDIGREE=INFLIGHT 29/08/98 - 21/08/99 HISTORY: DESCRIP=not significantly different from j6e16008u. HISTORY: DARKFILE=uref$j2g1549cu.r3h DARKCORR=COMPLETED HISTORY: PEDIGREE=INFLIGHT 16/02/1999 - 16/02/1999 HISTORY: DESCRIP=Pipeline dark: 120 frame superdark with hotpixels from HISTORY: 16/02/99 HISTORY: FLATFILE=uref$f4i1559cu.r4h FLATCORR=SKIPPED HISTORY: PEDIGREE=DUMMY 18/04/1995 HISTORY: DESCRIP=All pixels set to value of 1. Not flat-fielded. HISTORY: PC1: bias jump level ~0.100 DN. HISTORY: The following throughput tables were used: HISTORY: crotacomp$hst_ota_007_syn.fits, crwfpc2comp$wfpc2_optics_006_syn.fits, HISTORY: crwfpc2comp$wfpc2_lrf_004_syn.fits[wave#], HISTORY: crwfpc2comp$wfpc2_dqepc1_005_syn.fits, HISTORY: crwfpc2comp$wfpc2_a2d7pc1_004_syn.fits, HISTORY: crwfpc2comp$wfpc2_flatpc1_003_syn.fits HISTORY: The following throughput tables were used: HISTORY: crotacomp$hst_ota_007_syn.fits, crwfpc2comp$wfpc2_optics_006_syn.fits, HISTORY: crwfpc2comp$wfpc2_lrf_004_syn.fits[wave#], HISTORY: crwfpc2comp$wfpc2_dqewfc2_005_syn.fits, HISTORY: crwfpc2comp$wfpc2_a2d7wf2_004_syn.fits, HISTORY: crwfpc2comp$wfpc2_flatwf2_003_syn.fits HISTORY: The following throughput tables were used: HISTORY: crotacomp$hst_ota_007_syn.fits, crwfpc2comp$wfpc2_optics_006_syn.fits, HISTORY: crwfpc2comp$wfpc2_lrf_004_syn.fits[wave#], HISTORY: crwfpc2comp$wfpc2_dqewfc3_005_syn.fits, HISTORY: crwfpc2comp$wfpc2_a2d7wf3_004_syn.fits, HISTORY: crwfpc2comp$wfpc2_flatwf3_003_syn.fits HISTORY: The following throughput tables were used: HISTORY: crotacomp$hst_ota_007_syn.fits, crwfpc2comp$wfpc2_optics_006_syn.fits, HISTORY: crwfpc2comp$wfpc2_lrf_004_syn.fits[wave#], HISTORY: crwfpc2comp$wfpc2_dqewfc4_005_syn.fits, HISTORY: crwfpc2comp$wfpc2_a2d7wf4_004_syn.fits, HISTORY: crwfpc2comp$wfpc2_flatwf4_003_syn.fits CTYPE3: GROUP_NUMBER CD3_3: 1 CD3_1: 0 CD1_3: 0 CD2_3: 0 CD3_2: 0
FITS ファイルのデータ部分の取得
以下のコードでデータ部分を取得することができます。
サンプル FITS ファイルでは 200x200 で 4 つのイメージが格納されています。以下のコ
ードでは、1 つ目のデータを取得しています(data[0])。
from astropy.io import fits file_name = "data/WFPC2u5780205r_c0fx.fits" hdul = fits.open(file_name) data = hdul[0].data[0] print(data)
FITS データの描画
matplotlib を利用して、FITS データを描画します。
matplotlib のインストール
- pip インストール
pip install matplotlib
- poetry インストール
poetry add matplotlib
matplotlib での描画
以下のコードで FITS データを描画できます。
import matplotlib.pyplot as plt from astropy.io import fits file_name = "data/WFPC2u5780205r_c0fx.fits" hdul = fits.open(file_name) data = hdul[0].data[0] plt.figure(figsize=(10, 10)) plt.imshow(data, cmap="gray") plt.colorbar() plt.show() plt.close() hdul.close()
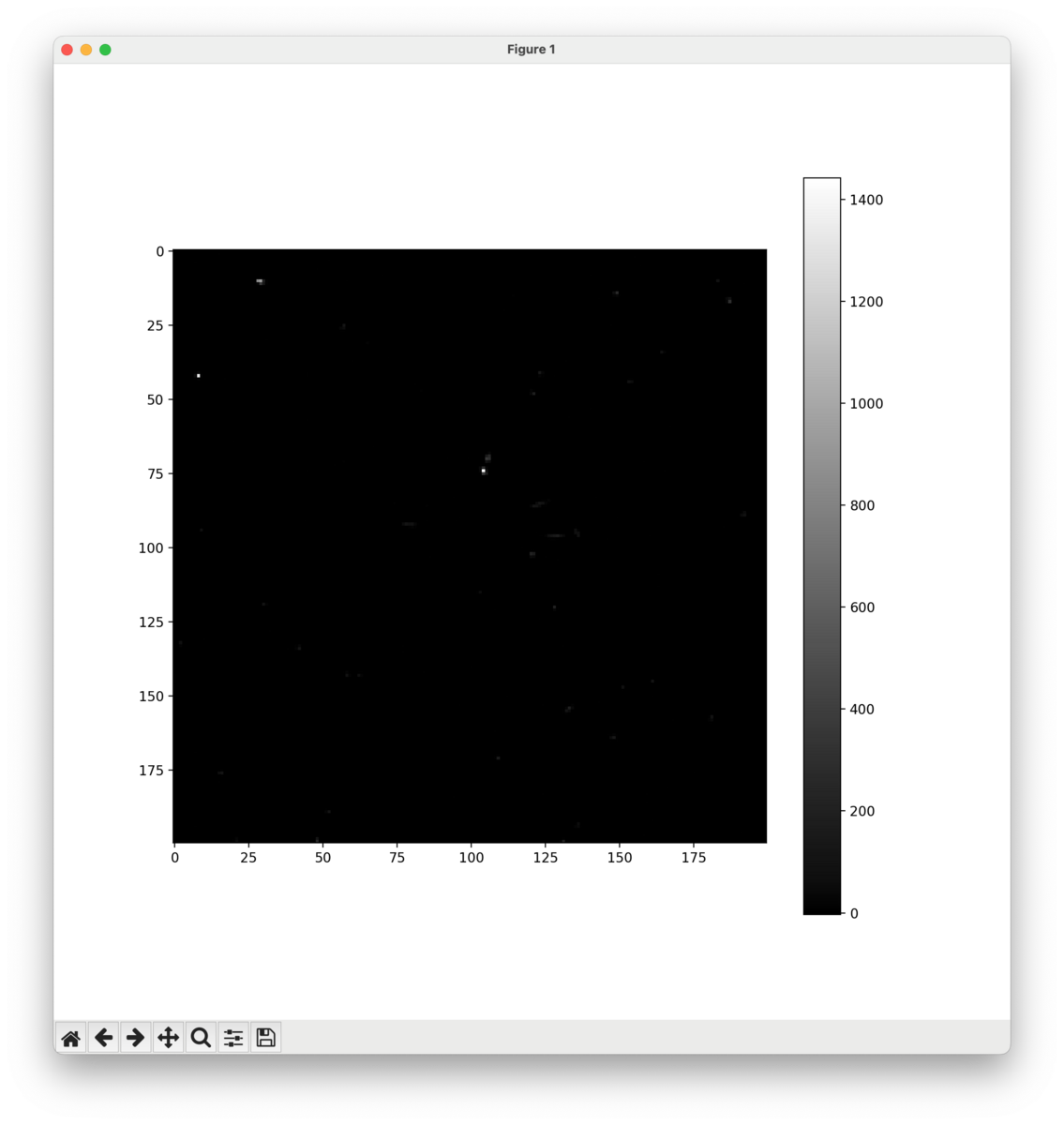
感想
今回、python で astropy を利用して FITS ファイルを読み込み、ヘッダー情報の取得、 データの取得、データの描画までまとめました。
ここまで操作できれば、あとの取り扱いはデータ処理になります。参考にしてください。
ではでは、また次回。


